
Les données environnementales
Les données environnementales ont été sélectionnées en fonction de leur pertinence par rapport à l’évènement de santé étudié (données de la littérature scientifique), de leur disponibilité et de leur intérêt pour le territoire d’étude.
Nos modèles de biosurveillance de la qualité des milieux
Au sein de notre laboratoire, ont été créées, validées et analysées des bases de données issues de la biosurveillance végétale et fongique des milieux, menée par le LSVF en partenariat avec l’Association pour la Prévention de la Pollution Atmosphérique (APPA).
- La biosurveillance lichénique de la qualité de l’air : Indice Biologique Lichen Epiphyte, imprégnation par les éléments traces (LSVF/APPA).
- La biosurveillance des poussières atmosphériques déposées sur les feuilles de peupliers (LSVF/APPA).
- La biosurveillance de la qualité des sols : mesure de la fluorescence chlorophyllienne, indice de nodulation, génotoxicité (LSVF).
Les données externes
En plus des données de biosurveillance générées par notre laboratoire, nous enrichissons également notre SIG des bases de données environnementales de surveillance physico-chimique et d’infrastructures anthropiques sources d’émissions, grâce à nos partenaires publics.
- Emissions et immissions atmosphériques (atmo Nord – Pas de Calais)
- Qualité des remblais urbains de la ville de Lille
- Sites et sols pollués ou potentiellement pollués (BASIAS/BASOL)
- Contamination des eaux souterraines (Banque ADES)
- Infrastructures routières, industrielles, urbaines et agricoles (IGN/PPIGE)
- Occupation du sol (CORINE Land Cover)
Les données sanitaires
Les données sanitaires recueillies par les équipes de cliniciens partenaires du programme sont déclarées auprès du Comité de Protection des Personnes (CPP) ou de la Commission nationale de l’informatique et des libertés (CNIL), puis fournies au LSVF en garantissant le respect de la confidentialité.
Les registres de santé, ainsi que les centres de référence régionaux permettent un recensement exhaustif (ou quasi exhaustif) des évènements de santé sur le territoire et la période concernés. Les cas recensés, ainsi que l’adresse de leur domicile au moment de la déclaration de l’événement sont utilisés pour le calcul d’indicateurs d’incidence à l’échelle des territoires (IRIS, commune, canton).
Les cohortes de population peuvent être mises en place pour le suivi biologique des polluants (sang, urines, cheveux, tissus) ou de paramètres de santé (capacités respiratoires, spermogrammes, …) pour un échantillon de la population générale. L’adresse du lieu d’habitation est alors recensée au moment de l’inclusion du candidat dans l’étude. Cette adresse est utilisée pour représenter l’évolution dans l’espace de ces paramètres biologiques.
Les données sociodémographiques
Les caractéristiques socioéconomiques sont prises en compte pour caractériser les inégalités sociales, au travers d’indices permettant une identification territorialisée des populations les plus vulnérables sur un plan socio-économique. S’appuyant sur les données socioéconomiques et démographiques mises à jour par l’INSEE (issues du recensement de la population notamment), plusieurs indices de défaveur sont aujourd’hui utilisés dans ce programme, quelques-uns sont présentés ci-dessous.
L’indice de Townsend (1987) est l’indicateur socio-économique le plus utilisé à l’échelle mondiale. Il intègre quatre notions : la proportion de chômeurs dans la population active (V1), la proportion de résidences principales occupées par plus d’une personne par pièce (V2), la proportion de résidences principales dont le ménage occupant n’est pas propriétaire (V3) et la proportion de ménages sans voiture (V4).
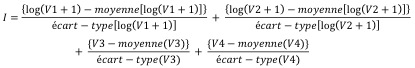
Indice de Townsend
L’indicateur de défaveur localisé (IDL) fut construit par le Laboratoire TVES de l’ULCO (EA4477) à partir d’une approche éco-sociologique, basant le choix des variables selon un critère bibliographique. Il tient compte de 14 variables traitant des différentes facettes de la défaveur : formes d‘emploi, exclusion de l’emploi, éducation, lien social, revenu et logement. Il est inspiré d’un indicateur reconnu, institutionnalisé et facilement appropriable : l’Indicateur de Santé Sociale des régions (ISS : Jany-Catrice & Zotti, 2009). L’IDL vise à situer un territoire par rapport à l’ensemble des territoires d’un espace de référence. Il s’agit donc d’un indicateur relatif et transposable, puisqu’une unité́ considérée comme défavorisée dans un espace A (par exemple une communauté́ urbaine) ne le sera pas nécessairement dans un espace B (une région).
Le French Ecological Deprivation Index (EDI) a été développé par Pornet et al. (2012). Basé sur une enquête européenne spécifiquement dédiée à l’étude de la défavorisation, il présente l’avantage de refléter l’expérience individuelle de défavorisation et d’être transposable à différents territoires au sein de l’Europe. Le score de cet indice est calculé selon la formule suivante :
Score = 0.11 x “Surpeuplement” + 0.34 x “Pas d’accès au chauffage central ou électrique” + 0.55 x “Non propriétaires” + 0.47 x “Chômage” + 0.23 x “Nationalité étrangère” + 0.52 x “Pas d’accès à une voiture” + 0.37 x “Ouvriers non qualifiés-ouvriers agricoles” + 0.45 x “Ménages avec au moins 6 personnes” + 0.19 x “Faible niveau d’étude” + 0.41 x “Familles monoparentales”.
Références bibliographiques
Jany-Catrice F & Zotti R. 2008. Les régions françaises face à leur santé sociale, contribution au débat. Institut pour le développement de l’information économique et sociale.
Pornet C, Delpierre C, Dejardin O, Grosclaude P, Launay L, Guittet L, Lang T & Launoy G. 2012. Construction of an adaptable European transnational ecological deprivation index: the French version. Journal of Epidemiology & Community Health 66, 982–989. doi:10.1136/jech-2011-200311
Townsend P. 1987. Deprivation. Journal of Social Policy, 16 (2) : 125-146.